Is this something I have to worry about?
To give some context, I’m creating a simple Microk8s cluster with one controller and one worker node.
I have two separate virtual machines that belong to the same private network of 192.168.1.0
I went ahead and installed Microk8s on both machines, tried a simple nginx deployment on kube-controller and made sure it’s working as intended. Now, I want to create a multi-node cluster so I followed the documentation.
kube-controller $ microk8s add-node
kube-worker $ microk8s join 192.168.1.1:25000/36a...7f8/14...6 --worker
kube-controller $ kubectl get nodes
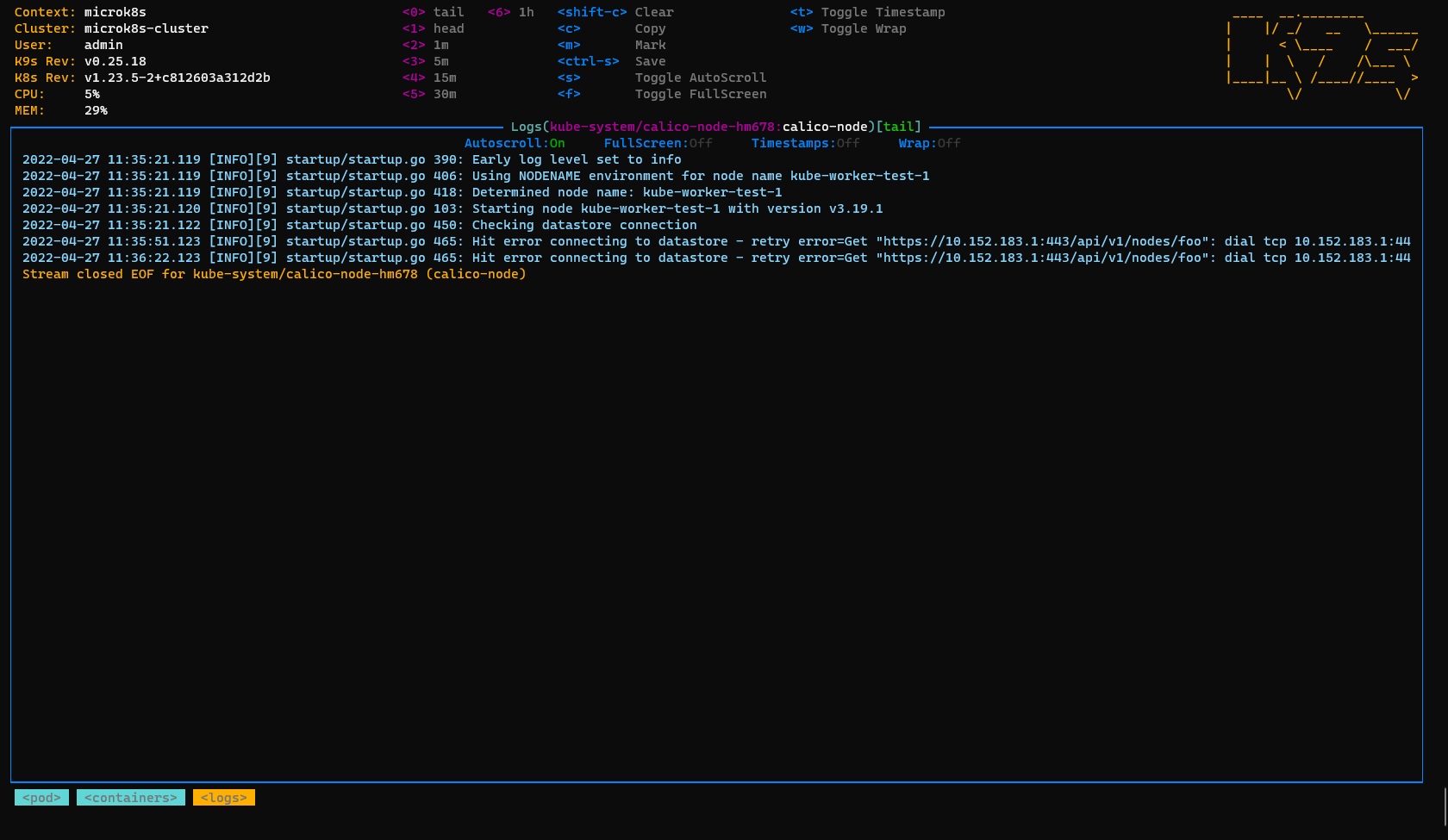
All is well so far. However, I could see that a pod automatically created by kube-worker-test-1 keeps crashing with:
Hit error connecting to datastore - retry error=Get “https://10.152.183.1:443/api/v1/nodes/foo”: dial tcp 10.152.183.1:44 ││ 3: i/o timeout
Is this an error or a bad configuration from my side? I’ve seen a similar thread but I don’t know if it’s the same thing. I’ve also seen a possible solution on GitHub about changing the pod-network-cidr but I don’t seem to understand it.
I’m still new to Kubernetes and MicroK8s so any input on the matter is very much appreciated.
I got the <kubernetes-server-cluster-ip> using kubectl get service kubernetes -o wide.
From kube-controller (192.168.1.1), I tried doing a curl and it responded successfully!
curl https://<kubernetes-server-cluster-ip>:443/api/v1/nodes/foo -k
From kube-worker-test-1 (192.168.1.2), I also tried doing a curl and here is the output:
curl https://<kubernetes-server-cluster-ip>:443/api/v1/nodes/foo -k # Did not respond
curl https://192.168.1.1:16443/api/v1/nodes/foo -k # Responded successfully!
Now I guess I’m looking for a way to pass 192.168.1.1:16443 as the datastore IP to the worker on 192.168.1.2
I found a /var/snap/microk8s/current/args/cni-network/calico-kubeconfig file which contains this config
clusters:
- name: local
cluster:
server: https://[10.152.183.1]:443
I tried changing the server key to https://192.168.1.1:16443 for both the controller and the worker but, then restarted microk8s but still no luck. The logs still show that https://10.152.183.1:443 is being used.
I haven’t used microkis but from doc
The list of API servers is stored in /var/snap/microk8s/current/args/traefik/provider.yaml . Please, review this list right after the join operation completes to verify all control plane endpoints are there. If your API servers are behind a load balancer you will need to replace the detected endpoints in this file with the entry your provided by the load balancer.
Seems that do some magic viewing your interfaces… If k8s try to do magic maybe it’s will do fail too…
My advice from de distance  try to do from the beginning changing this file before to add the first node
try to do from the beginning changing this file before to add the first node
Hope it’s help
No luck unfortunately. Although I managed to narrow down the problem I think.
You put in /var/snap/microk8s/current/args/traefik/provider.yaml 192.168.1.1 and view the change in /var/snap/microk8s/current/args/cni-network/calico-kubeconfig?? and no comunication?
I’ve seen that /var/snap/microk8s/current/args/traefik/provider.yaml was configured successfully by microk8s. I also tried overriding and removing then re-adding the node but it still won’t work.
One interesting thing I noticed is that /var/snap/microk8s/current/args/cni-network/calico-kubeconfig always gets overridden when I restart the cluster.
# Kubeconfig file for Calico CNI plugin.
apiVersion: v1
kind: Config
clusters:
- name: local
cluster:
server: https://[10.152.183.1]:443 # => I tried setting it to https://192.168.1.1:16443 but it always changes back to this value.
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJ...
...