Hi everyone,
I have some problems in using pyspark in spark cluster via kubernetes bitnami helm chart,
every code with java or scala run correctly but some codes run with pyspark will not resulted correctly.
my spark cluster creation process has written at this link medium
e.g. python code (ctp.py) :
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WritingParquet").getOrCreate()
df = spark.read.csv("/path/to/parquet/file.csv")
df.show()
df.write.parquet("a.parquet")
running bash command :
kubectl exec -it kayvan-release-spark-master-0 -- ./bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://kayvan-release-spark-master-0.kayvan-release-spark-headless.default.svc.cluster.local:7077
ctp.py
result & problem ![]() :
:
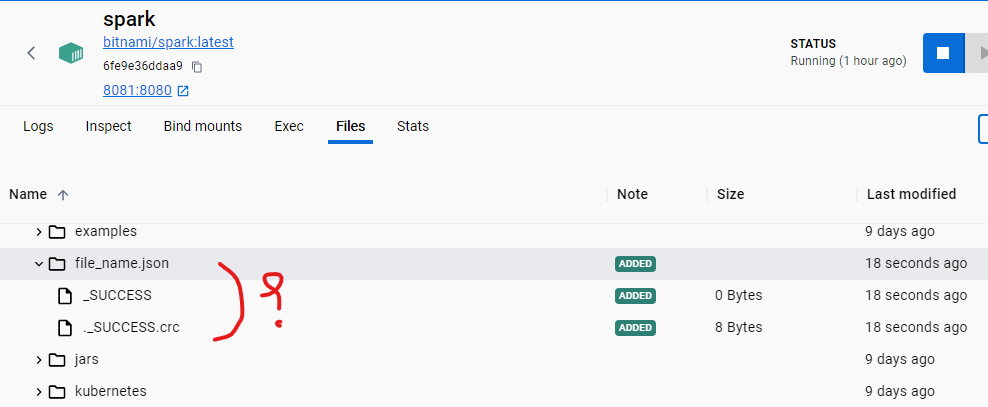
df.show() —> shows the list correctly and the folder a.parquet is created with _SUCCESS and _SUCCESS.crc files but *.parquet file will not exist, while the result with scala shell is correct !
problem 2 :
and also the bin/pyspark shell will not run inside pod (container) !
I test above code with docker compose too with bitnami image and the result was the same fault in creation of *.parquert file :
csv read success :

parquet file creation failure :

docker-compose.yml :
version: '3.6'
services:
spark:
container_name: spark
image: bitnami/spark:latest
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- SPARK_USER=spark
ports:
- 127.0.0.1:8081:8080
spark-worker:
image: bitnami/spark:latest
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark:7077
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=2
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- SPARK_USER=spark
docker run :
docker-compose up --scale spark-worker=2
ctp.py :
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WritingParquet").getOrCreate()
df = spark.read.option("header", True).csv("csv/file.csv")
df.show()
df.write.mode('overwrite').parquet("a.parquet")
spark submit :
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://35368355157f:7077 csv/ctp.py
I create a issue in bitnami github repo too : link
please help me ![]()